HumanPose- CMU Panoptic Dataset
Preprocessing and Exploratory Data Analysis
2021-07-27 10:10
HumanPose: Panoptic Data
AUTHOR: SungwookLE
DATE: ‘21.7/28
GIT REPO: CMU-Perceptual-Computing-Lab
DOCU: docu
DATASET: Panoptic
HumanPose 분야 관련 용어
-
- Top-down approach
- Human Detector 알고리즘을 이용해서 사람을 먼저찾고, 찾은 사람을 대상으로 keypoint 학습하는 구조, 연산 속도가 오래 걸리고, Human Detector의 성능에 의해 전체 알고리즘의 성능이 결정됨
-
- Bottom-up approach
- OpenPose 논문에서 사용하는 방법으로 Greedy 하게 사람들의 존재까지도 찾게끔 학습시키는 구조, Multi Person에서 속도가 빠르고, 정확도도 높다.
- Detection 알고리즘 성능 평가 방법: REF1, REF2
- Precision, Recall, Accuracy, F1 Score
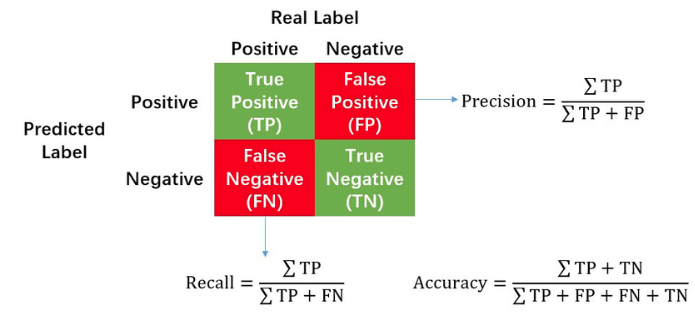
- Precision은 참으로 예측한 것 중 정답의 비율 = How man selected item’s are relevant
- Recall은 참인 데이터 중 정답의 비율 = How many relevant item’s are selected
- F1 Score는: Precision과 recall의 조화평균
$F1 Score= 2*(Precision * Recall)/(Precision + Recall)$ - PR커브는 confidence 레벨에 대한 threshold 값의 변화에 의한 성능을 평가하는 방법이다. (recall값에 따른 precision 값의 변화)
- AP(Average Precision)으로 PR커브의 아래 면적을 의미한다.
- mAP(mean Average Precision): class가 여러개인 경우 클래스당 AP를 구하여 평균값을 사용할 수 있다.
- IoU(Intersection over union) 중첩되는 박스의 비율
- PCK: Detected-joint is considered correct if the distance between the predicted and the true joint is within a certain threshold. PCK@0.2 는 threshold 가 0.2 * torso diameter 로써, 여기서 torso 는 사람의 몸통이다. Percentage of Correct Keypoints
- PCKh@0.5: threshold = 50% of the head segment length(head bone link) threshold 로써 몸통이 아닌 머리 부분의 길이를 사용한 변형 평가 지표이다. 보통 PCKh @ 0.5 를 많이 사용하는 추세
- AP@0.5 : IoU 의 threshold 가 0.5 일 때
- MPJPE: MPJPE는 모든 관절의 추정 좌표와 정답 좌표의 거리(단위 : mm)를 평균하여 산출되는 지표이다. 이것이 작을 수록 정확도가 좋다고 말할 수 있다. Estimated and groundtruth 3D Pose의 root 관절(일반적으로 골반)을 정렬 한 후 계산한다. 관절은 또한 root 관절로 정규화된다. Mean Per Joint Position Error
HumanPose 관련 논문
[1] 오픈포즈(Keypoint) 논문 (CMU): https://arxiv.org/pdf/1812.08008.pdf
[2] 오픈포즈 네트워크 설계 (CMU): https://arxiv.org/pdf/1602.00134.pdf
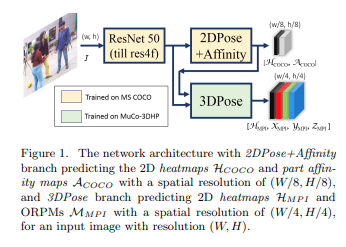
[3] 3D Pose 추출 (Single-Shot Multi-Person 3D Pose): https://arxiv.org/pdf/1712.03453.pdf
1. System Description

- 480 VGA cameras, 640 x 480 resolution, 25 fps, synchronized among themselves using a hardware clock
- 31 HD cameras, 1920 x 1080 resolution, 30 fps, synchronized among themselves using a hardware clock, timing aligned with VGA cameras
- 10 Kinect Ⅱ Sensors. 1920 x 1080 (RGB), 512 x 424 (depth), 30 fps, timing aligned among themselves and other sensors
- 5 DLP Projectors. synchronized with HD cameras
- Dataset Size: 65 sequences (5.5 hours) and 1.5 millions of 3D skeletons are available.
2. Video, Image, Keypoint Data Preparation
2-1. 데이터 다운로드
CMU-Perceptual-Computing-Lab를 clone하면 Panoptic 데이터셋을 다룰 수 있는 여러가지 bash파일(./scripts)이 들어있다. bash를 활용하여 (예시)./scripts/getData.sh 171204_pose1_sample 실행하여 데이터 다운로드 가능하다.
2-2. 데이터셋 구성
getData.sh는 HD/VGA Video, Calibration 정보를 다운로드 하는 것이고,
비디오에서 이미지와 3D keypoint는 extractAll.sh를 통해서 생성(압축해제)된다.
(예시)./scripts/extractAll.sh 171204_pose1_sample
| No. | Folder Route | 설명 | 생성 순서 |
|---|---|---|---|
| 1 | /hdVideos/hd_00_XX.mp4 | #Synchronized HD video files (31 views) | getData.sh 이후 |
| 2 | /vgaVideos/ | #Synchrponized VGA video files | getData.sh 이후 |
| 3 | /calibration_171204_pose1_sample.json | #Camera calibration files | getData.sh 이후 |
| 4 | /hdPose3d_stage1_coco19.tar | #3D Body Keypoint Data (coco19 keypoint definition) | extractAll.sh 실행하면 압축이 해제됨 |
| 5 | /hdFace3d.tar | #3D Face Keypoint Data | extractAll.sh 실행하면 압축이 해제됨 |
| 6 | /hdHand3d.tar | #3D Hand Keypoint Data | extractAll.sh 실행하면 압축이 해제됨 |
| 7 | /hdImgs | #extracted image from hdVideos | extractAll.sh 실행하면 비디오에서 (25fps)로 추출됨 |
| 8 | /vgaImgs | #extracted image from vgaVideos | extractAll.sh 실행하면 비디오에서 (29.97fps)로 추출됨 |
2-3. 이미지와 3D keypoint data 추출
(예시)./scripts/extractAll.sh 171204_pose1_sample 실행하여 비디오 파일의 이미지를 추출하고 3D keypoint의 (tar파일) 압축을 해제한다.
예를 들어, 171204_pose1_sample/hdImgs/00_00/00_00_00000000.jpg 와 대응되는 keypoint json은 171204_pose1_sample/hdPose3d_stage1_coco19/body3DScene_00000000.json 이다.
2-4. 3D keypoint 라벨링 데이터 Format
Skeleton Output Format
Skeleton(3D keypoint) 라벨링 데이터는 아래 예시와 같이 구성되어 있다.
{ "version": 0.7,
"univTime" :53541.542,
"fpsType" :"hd_29_97",
"bodies" :
[
{ "id": 0,
"joints19": [-19.4528, -146.612, 1.46159, 0.724274, -40.4564, -163.091, -0.521563, 0.575897, -14.9749, -91.0176, 4.24329, 0.361725, -19.2473, -146.679, -16.1136, 0.643555, -14.7958, -118.804, -20.6738, 0.619599, -22.611, -93.8793, -17.7834, 0.557953, -12.3267, -91.5465, -6.55368, 0.353241, -12.6556, -47.0963, -4.83599, 0.455566, -10.8069, -8.31645, -4.20936, 0.501312, -20.2358, -147.348, 19.1843, 0.628022, -13.1145, -120.269, 28.0371, 0.63559, -20.1037, -94.3607, 30.0809, 0.625916, -17.623, -90.4888, 15.0403, 0.327759, -17.3973, -46.9311, 15.9659, 0.419586, -13.1719, -7.60601, 13.4749, 0.519653, -38.7164, -166.851, -3.25917, 0.46228, -28.7043, -167.333, -7.15903, 0.523224, -39.0433, -166.677, 2.55916, 0.395965, -30.0718, -167.264, 8.18371, 0.510041]
}
]
}
- id: A unique subject index within a sequence: Skeletons with the same id across time represent temporally associated moving skeletons (an individual). However, the same person may have multiple ids
- joint19: 19 3D joint locations, formatted as [x1,y1,z1,c1,x2,y2,z2,c2,…] where each c ispanopticHDjoint confidence score. (c는 confidence score!)
19개의 joint(keypoint)는 아래의 순서로 기록되어 있다.
0: Neck
1: Nose
2: BodyCenter (center of hips)
3: lShoulder
4: lElbow
5: lWrist,
6: lHip
7: lKnee
8: lAnkle
9: rShoulder
10: rElbow
11: rWrist
12: rHip
13: rKnee
14: rAnkle
15: lEye
16: lEar
17: rEye
18: rEar
Note that this is different from OpenPose output order, although our method is based on it.
2-5. 데이터 다운로드
- CMU Panoptic Dataset Browse 미리 데이터를 살펴본 후 Panoptic Studion DB: Released Sequences 에 있는 리스트면 다운로드 가능하니 선택하여 다운로드 받거나, 전체 데이터를 다운 받을 수 있다.
방법1: ./scripts/getDB_panopticHD_ver1_2.sh 를 실행하는 방법으로 전체 다운로드가 가능한데 해당 bash 파일을 그대로 실행할 경우 비디오 데이터 다운로드가 안되어 이미지 데이터를 얻을 수가 없으므로 VGA($vgaVideoNum), HD 비디오($hdVideoNum) 파일의 개수를 0이 아닌 숫자로 설정한다.
방법2: Browse에서 적절한 데이터를 선택한 후 (예시)./scripts/getData.sh 171026_cello1 $vgaVideoNum $hdVideoNum 를 입력하여 선택 다운로드 한다.
다운로드 후에는 2-3의 과정을 통해 이미지 데이터와 키포인트 데이터를 추출한다.
3. panoptic 툴 예제 사용
3-1. 3Dkeypoint_reprojection_hd.ipynb
몇가지 마이너한 코드 수정을 하면 바로 실행가능
달려있는 여러 카메라 이미지에 맞게끔 keypoint 데이터를 warp transform 해서 이미지에 reprojection하는 라이브러리
아래 예시는 0번째 HD 카메라에 reprojection한 것이고 31 개의 카메라 존재함
실행결과: 
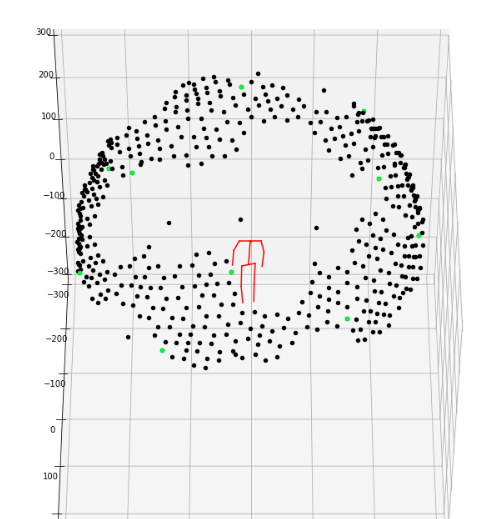
3-2. 3Dkeypoint_3dview.ipynb
몇가지 마이너한 코드 수정을 하면 바로 실행가능
keypoint 데이터(x,y,z)를 3차원으로 플롯팅해주는 라이브러리
실행결과: 
4. 2D NET
4-1. RealTime 2D Openpose
-
Real-time 2D Multi-Person Pose Estimation on CPU: Lightweight OpenPose 해당 레포에 설명이 잘되어 있고, 논문[3]에 대한 repo도 링크로 제공하고 있음
- OPENVINO로 c++ demo를 해보려고 했는데, 실패함,, openvino 종속성 문제 (7/27)
python demo.py --checkpoint-path <path_to>/checkpoint_iter_370000.pth --video 0를 실행하여 한번 돌려보았는데 속도는 매우 빠르고 시각적인 데모를 제공하네


5. 3D NET
5-1. RealTime 3D Openpose
질문:
-
- 데이터 전처리
- 첫번째, 데이터 다운로드 하는
bash정리
두번째, keypoint 라벨링(annotation) 데이터 네트워크에 맞게끔 준비 세번째, panoptic data에서 hd camera 등을 몇개 입력할 것인지 정해야 함
자동차도메인을 생각하면 카메라는 1개인데, 카메라의 개수가 많아질수록 성능은 좋아질 것임
Vision-transformer
* 데이터셋 정리 (Human3.6 or CMU panoptic)
- Human3.6이 Single Person dataset이긴 한데, CMU panoptic이 문서가 더 잘 되어 있고
향후, 학습 차원에서도 multi-person dataset인 CMU 걸 쓰는 게 어떨까 싶네요.
- Train / Valid / Test Split
- 데이터 전처리 코드 작성, 툴 활용 (https://github.com/CMU-Perceptual-Computing-Lab/panoptic-toolbox) (Matlab or Python)
Input – RGB image, Output – 각 키포인트 18개 x, y, z 좌표로 이루어진 열 벡터 (18*3 = 54차원)
1-1) 이미지에 backbone을 reprojection 한 이미지 데이터가 필요한 것인가? [X]
1-2) 아니면, 데이터를 panoptic bash 이용하여 다운로드 하면되고, 아래의 전처리를 진행해 주어야 함
-> panoptic 데이터는 여러 각도에서의 RGB이미지와 keypoint 19*4(x,y,z,confidence) 매트릭스로 이루어져 있음
-> 이 라벨 데이터를 그대로 쓸거면 라벨링 포맷도 바꿀 필요는 없겠지만, 바꾼다면 prepare_annotation 커스텀 라이브러리가 필요
-> train/vaild/test 나눌 make_val_subset 커스텀 라이브러리 필요하고,
-> 2D NET 과 3D NET 의 피드데이터구조는 똑같아야 하는가?: 똑같이 RGB 이미지
-> 3D NET만 추가학습하는 것이니까, 라벨을 CMU_panoptic에서 가져오면 됨
1-3) 꽤 용량이 큰데, 어떻게 AI서버에 업로드 하지?
1-4) panoptic은 제한된 데이터 밖에 없는데(3D keypoint 잇는 데이터이긴 함), COCO dataset format은 2D key만 있음, 2D Pose Estimation 네트워크 학습에만 쓰는거고(프리트레인드 네트워크를 그대로 들고온다고 하면 2D데이터 학습은 필요하지 않음) 추가적인 3D 키포인트 학습 때 CMU_panoptic 데이터를 쓰면 되겠네
