Kaggle
DataAnalysis Pretest
Keras Feed Input(n_dim=4), Overfit & Underfit
2021-06-30 10:10
DS_Test
- AUTHOR: SungwookLE
-
DATE: ‘21.6/30
- PROBLEM
1) 아래 코드의 문제점을 적고 해결하라 (한줄추가)X_train = X_train.reshape((X_train.shape[0],X_train.shape[1],X_train.shape[2],1)) #추가한 코드 X_test = X_test.reshape((X_test.shape[0],X_test.shape[1],X_test.shape[2],1)) #추가한 코드
import tensorflow as tf
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense,Conv2D,Flatten,MaxPool2D
(X_train, y_train), (X_test,y_test) = mnist.load_data()
print("BEFORE SHAPE IS {}".format(X_train.shape))
X_train = X_train.reshape((X_train.shape[0],X_train.shape[1],X_train.shape[2],1)) #추가한 코드
X_test = X_test.reshape((X_test.shape[0],X_test.shape[1],X_test.shape[2],1)) #추가한 코드
print("AFTER SHAPE IS {}".format(X_train.shape))
model_lenet = Sequential()
model_lenet.add(Conv2D(input_shape=(28,28,1),kernel_size=(5,5),strides=(1,1),filters=32,padding='same', activation='relu'))
# print('Conv2D:\t{0}'.format(model_lenet.output_shape))
model_lenet.add(MaxPool2D(pool_size=(2,2),strides=(2,2),padding='same'))
model_lenet.add(Conv2D(kernel_size=(5,5),strides=(1,1),filters=48,padding='same', activation='relu'))
model_lenet.add(MaxPool2D(pool_size=(2,2),strides=(2,2),padding='same'))
model_lenet.add(Flatten())
model_lenet.add(Dense(256,activation='relu'))
model_lenet.add(Dense(84,activation='relu'))
model_lenet.add(Dense(10,activation='softmax'))
model_lenet.compile(loss='sparse_categorical_crossentropy',optimizer='adam')
model_lenet.fit(X_train, y_train, batch_size=32, epochs=3)
BEFORE SHAPE IS (60000, 28, 28)
AFTER SHAPE IS (60000, 28, 28, 1)
Conv2D: (None, 28, 28, 32)
Epoch 1/3
60000/60000 [==============================] - 303s 5ms/step - loss: 14.5466
Epoch 2/3
60000/60000 [==============================] - 325s 5ms/step - loss: 14.5463
Epoch 3/3
60000/60000 [==============================] - 319s 5ms/step - loss: 14.5463
<keras.callbacks.History at 0x7f3614b6bcc0>
test=model_lenet.predict(X_test)
one_hot_y = tf.one_hot(y_test, 10)
out=one_hot_y.eval(session=tf.Session())
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
sns.set()
df = pd.DataFrame(out-test)
- EPOCH1: ACCURACY IS 10.09 %
EPOCH2: ACCURACY IS 9.74 %
count=0
for i in range(len(df)):
temp=df.iloc[i].values
for j in temp:
if (j==-1):
count+=1
print("ACCURACY IS {:.2f} %".format(100-count/len(df)*100))
ACCURACY IS 9.74 %
1번 서술
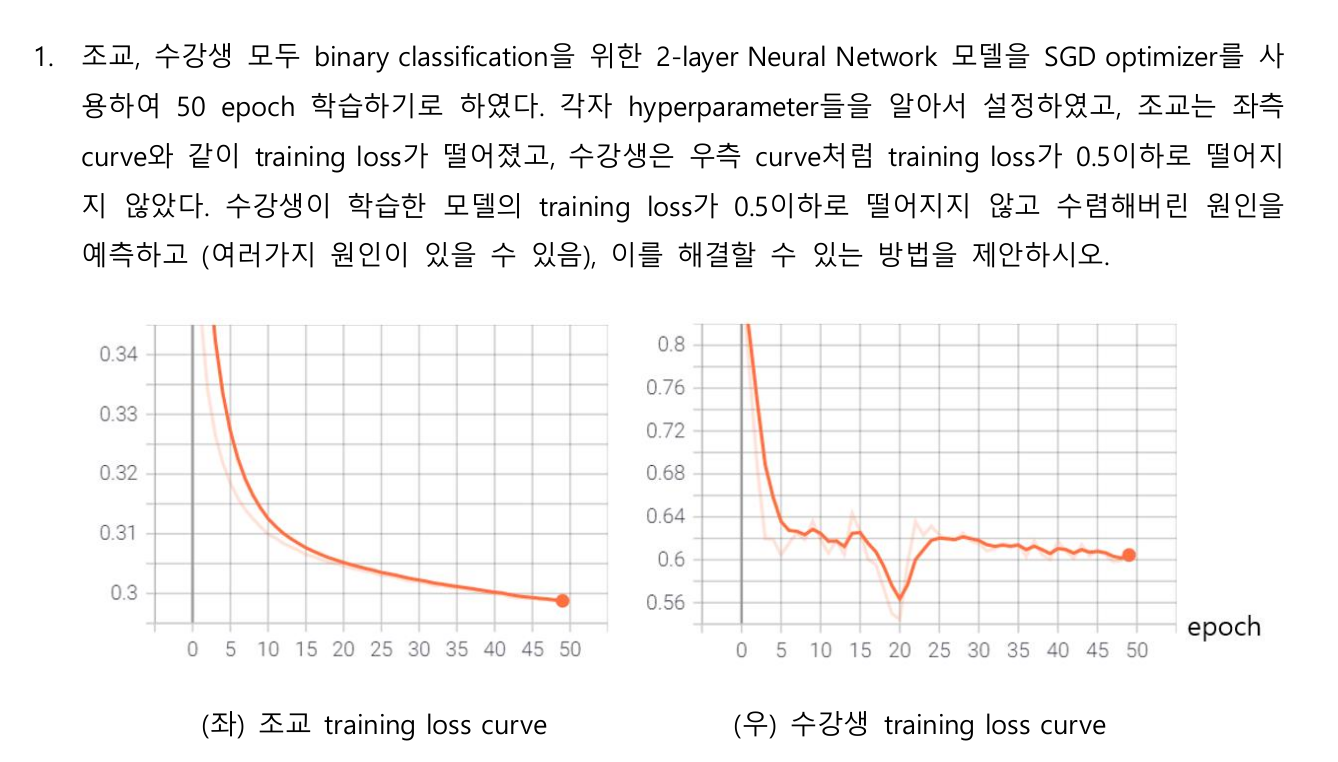
- 상황: training loss가 0.5이하로 떨어지지 않고 수렴
- 원인 예측: 학습이 언더피팅 되어 수렴하고 있고, 모델이 데이터의 특징을 학습하고 있지 못하여 발생 (Low Variance, High Bias)
- 해결 방안: 언더피팅을 방지하기 위한 방법 접근 (Bias 낮추기)
1)모델의 파라미터 개수를 증가하여, 모델의 복잡도를 증가시켜 데이터가 잘 학습될 수 있도록 한다.
2) 인풋 데이터의 Normalization을 수행하여, Feed data의 Scale을 동일한 수준에서 수행하고, 모델을 학습시킨다.
3) 러닝레이트 스케쥴링, Epoch가 진행됨에 따라 점직적으로 러닝레이트를 감소시켜 모델을 학습시킨다.
2번 서술
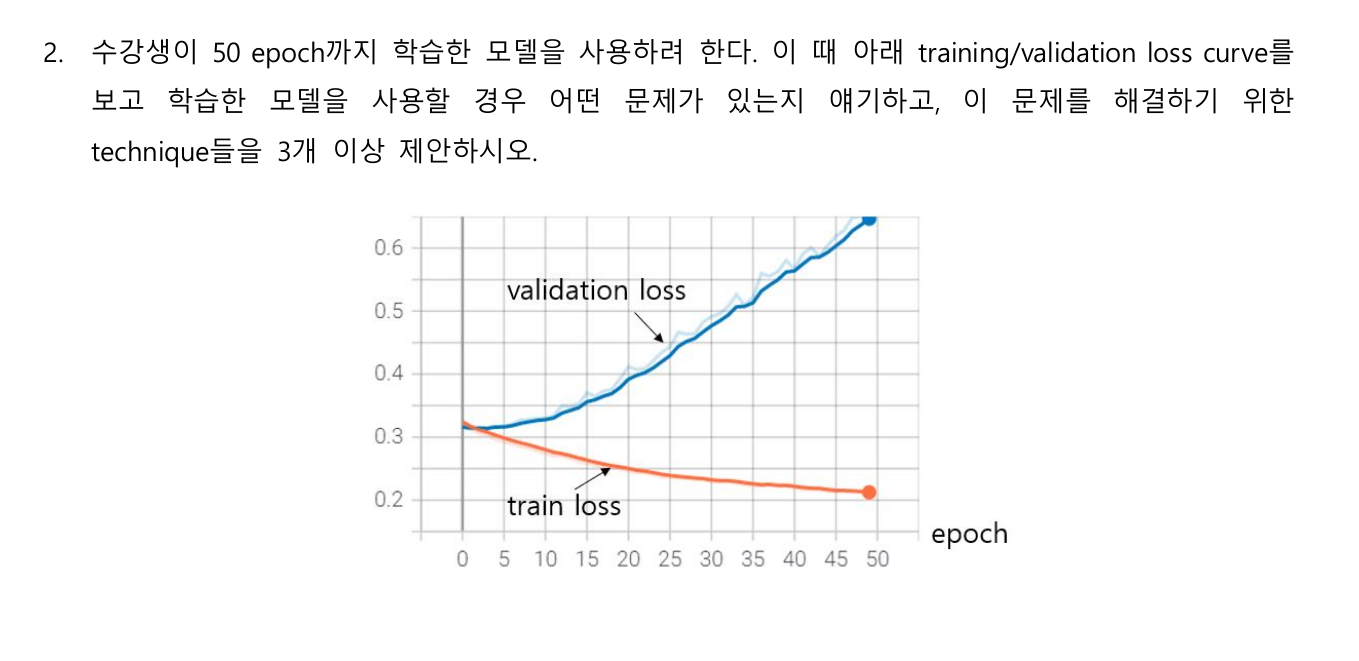
- 문제: Training 데이터에 오버피팅 되어 (High Variance, Low Bias), Validation에서는 제대로 된 예측이 안되고 있음을 확인할 수 있다. 해당 모델을 사용할 경우, 새로운 데이터에서 제대로된 예측이 되지 않는다.
- 해결방법: 오버피팅 방지하기 위한 방법 접근(Variance 낮추기)
1) Cost function을 기존 에러 제곱만을 쓰고 있다면, weighting parameter 의 값도 추가하는, Regularization을 적용한다. 이렇게 하면 Variance가 낮아져, 오버피팅을 방지할 수 있다. (L1-Regular, L2-Regular 등)
2) Dropout 적용: 오버피팅이 되는 것을 방지하기 위해, 뉴럴 노드의 학습 과정에서 random하게 dropout 시켜, 오버피팅을 방지할 수 있다.
3) Neural Layer 의 파라미터 개수 줄이기: 파라미터의 개수를 줄여, 모델의 복잡성을 낮춰 Variance 를 감소시켜 오버피팅을 방지할 수 있다.
3번 서술

- 문제 원인: 모델 Feed 데이터의 형태가 Conv Layer의 인풋 데이터 사이즈 맞지 않기 때문에 위와 같은 에러가 발생하였다. 따라서, 이를 해결하기 위해 Feed Data의 shape을 아래와 같이 변경해준다.
- 추가할 코드:
X_train = X_train.reshape((X_train.shape[0],X_train.shape[1],X_train.shape[2],1)) X_test = X_test.reshape((X_test.shape[0],X_test.shape[1],X_test.shape[2],1))끝

sungwook
Mr